从字面上看:区块链是由一个个记录着各种信息的小区块链接起来组成的一个链条,类似于我们将一块块砖头叠起来,而且叠起来后是没办法拆掉的,每个砖头上面还写着各种信息,包括:谁叠的,什么时候叠的,砖头用了什么材质等等,这些信息你也没办法修改。
从计算机上看:区块链是一种比较特殊的分布式数据库。分布式数据库就是将数据信息单独放在每台计算机,且存储的信息的一致的,如果有一两台计算机坏掉了,信息也不会丢失,你还可以在其他计算机上查看到。
区块链是一种分布式的,所以它是没有中心点的,信息存储在所有加入到区块链网络的节点当中,节点的数据是同步的。节点可以是一台服务器,笔记本电脑,手机等。
你要知道的是这些节点的存储的数据都是一模一样。

区块链特性
去中心化:因为它是分布式存储的,所以不存在中心点,也可以说各个节点都是中心点,生活中应用就是不需要第三方系统了(银行、支付宝、房产中介等都属于第三方)。
开放性:区块链的系统数据是公开透明的,每个人都可以参与进来,比如租房子,你可以知道这个房子以前的出租信息,有没出现过问题,当然这里头的一些个人私有信息是加密的。
自治性:区块链采用基于协商一致的规范和协议(比如一套公开透明的算法),然后各个节点就按照这个规范来操作,这样就是所有的东西都有机器完成,就没有人情成分。 使得对"人"的信任改成了对机器的信任,任何人为的干预不起作用。
信息不可篡改:如果信息存储到区块链中就被永久保存,是没办法去改变,至于 51% 攻击,基本不可能实现。
匿名性:区块链上面没有个人的信息,因为这些都是加密的,是一堆数字字母组成的字符串,这样就不会出现你的各种身份证信息、电话号码被倒卖的现象。
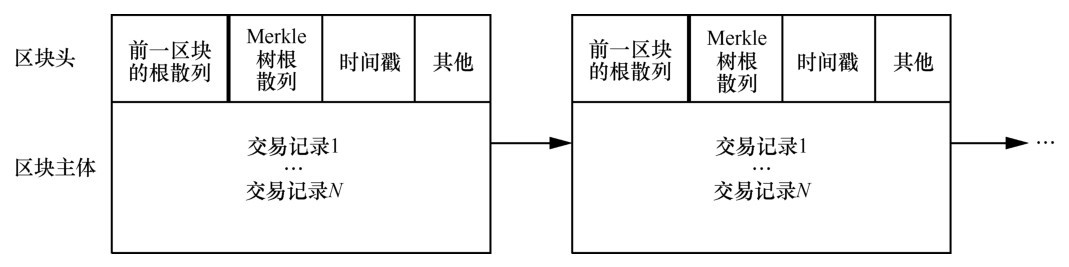
区块结构
区块包含两个部分:
1、区块头(Head):记录当前区块的元信息
2、区块体(Body):实际数据
包含数据如下图所示:
区块链如何工作
我们以转账为例:
目前我们转账都是中心化的,银行是一个中心化账本,例如 A 账号里有 400 块钱,B 账号里有 100 块钱。
当 A 要转 100 块钱给 B 时,A 要通过银行提交转账申请,银行验证通过后,就从 A 账号上扣除 100 块,B 账号增加 100 块。
计算后 A 账号扣除 100 后余额为300元,B 账号加上 100 后余额为 200 元。
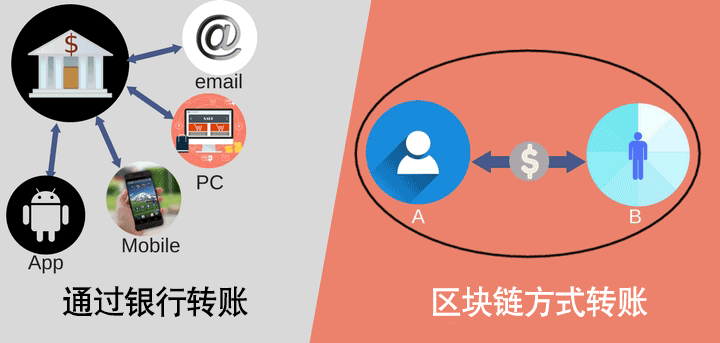
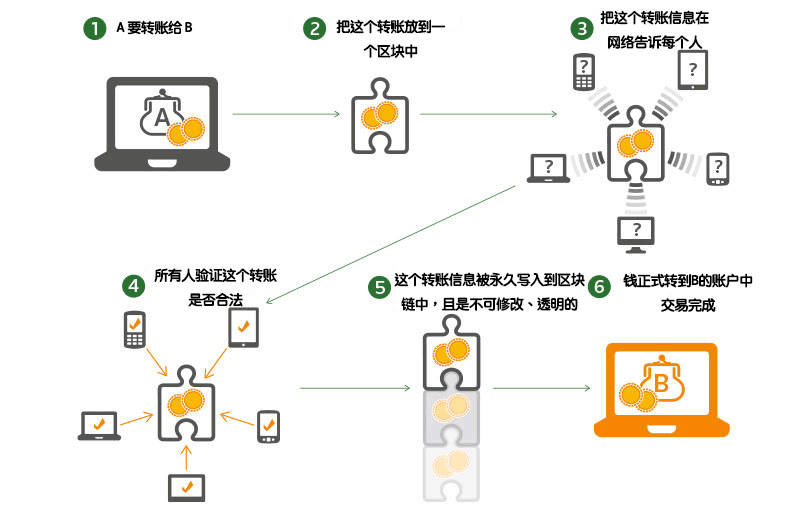
区块链上转账的步骤则是:A 要转账给 B 100 块钱,A 就会在网络上把要转账的这个信息告诉大家,大家会去查看 A 的账户上是否有足够的钱去完成这个转账,如果验证通过后,大家就把这个信息都记录到自己的电脑上区块链中,且每个人记入的信息都是同步一致的,这样 A 就顺利将 100 块钱转移到了 B 的账户上。可以看到这中间并没有银行啥事。
相关问题
区块链与比特币关系?
比特币2009年被中本聪提出,然后参考了比特币的实现提炼出了区块链的技术。
如果说比特币是面条,那么区块链就是面粉,后面大家发现面粉除了能做面条还可以做馒头跟包子。
为啥我要帮你存储区块信息?
无利不起早,简单说就是你帮我存储信息,我给你相应的报酬。
区块链需要了解的关键技术点?
通过 Hash 与 非对称加密来保障数据无法被篡改:
-
Hash:y = hash(x),对 x 进行哈希运算得出 y,可以隐藏原始信息 x,因为你没办法通过 y 来算出 x,从而做到匿名性。
-
非对称加密:公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。
共识算法:保障节点与节点之间的数据一致性。
有没一两句话能说明白区块链的?
有的。
麻将作为中国传统的区块链项目,四个矿工一组,先碰撞出13个数字正确哈希值的矿工可以获得记账权并得到奖励。

约定
在开始之前我们来约定一下本文所使用的 Python 版本。默认用的是 Python 3,也就是说:本文所定义的类都是新式类。如果你用到是 Python 2 的话,记得继承 object:# 默认, Python 3
class A:
pass
# Python 2
class A(object):
pass
Python 3 和 Python 2 的另一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
# 默认,Python 3
class B(A):
def add(self, x):
super().add(x)
# Python 2
class B(A):
def add(self, x):
super(B, self).add(x)
所以,你如果用的是 Python 2 的话,记得将本文的 super() 替换为 suepr(Class, self) 。
如果还有其他不兼容 Python 2 的情况,我会在文中注明的。
单继承
在单继承中 super 就像大家所想的那样,主要是用来调用父类的方法的。
class A:
def __init__(self):
self.n = 2
def add(self, m):
print('self is {0} @A.add'.format(self))
self.n += m
class B(A):
def __init__(self):
self.n = 3
def add(self, m):
print('self is {0} @B.add'.format(self))
super().add(m)
self.n += 3
你觉得执行下面代码后, b.n 的值是多少呢?
b = B() b.add(2) print(b.n)
执行结果如下:
self is <__main__.B object at 0x106c49b38> @B.add self is <__main__.B object at 0x106c49b38> @A.add 8
这个结果说明了两个问题:
- 1、super().add(m) 确实调用了父类 A 的 add 方法。
- 2、super().add(m) 调用父类方法 def add(self, m) 时, 此时父类中 self 并不是父类的实例而是子类的实例, 所以 b.add(2) 之后的结果是 5 而不是 4 。
不知道这个结果是否和你想到一样呢?下面我们来看一个多继承的例子。
多继承
这次我们再定义一个 class C,一个 class D:
class C(A):
def __init__(self):
self.n = 4
def add(self, m):
print('self is {0} @C.add'.format(self))
super().add(m)
self.n += 4
class D(B, C):
def __init__(self):
self.n = 5
def add(self, m):
print('self is {0} @D.add'.format(self))
super().add(m)
self.n += 5
下面的代码又输出啥呢?
d = D() d.add(2) print(d.n)
这次的输出如下:
self is <__main__.D object at 0x10ce10e48> @D.add self is <__main__.D object at 0x10ce10e48> @B.add self is <__main__.D object at 0x10ce10e48> @C.add self is <__main__.D object at 0x10ce10e48> @A.add 19
你说对了吗?你可能会认为上面代码的输出类似:
self is <__main__.D object at 0x10ce10e48> @D.add self is <__main__.D object at 0x10ce10e48> @B.add self is <__main__.D object at 0x10ce10e48> @A.add 15
为什么会跟预期的不一样呢?下面我们将一起来看看 super 的奥秘。
super 是个类
当我们调用 super() 的时候,实际上是实例化了一个 super 类。你没看错, super 是个类,既不是关键字也不是函数等其他数据结构:
>>> class A: pass ... >>> s = super(A) >>> type(s) <class 'super'> >>>
在大多数情况下, super 包含了两个非常重要的信息: 一个 MRO 以及 MRO 中的一个类。当以如下方式调用 super 时:
super(a_type, obj)
MRO 指的是 type(obj) 的 MRO, MRO 中的那个类就是 a_type , 同时 isinstance(obj, a_type) == True 。
当这样调用时:
super(type1, type2)
MRO 指的是 type2 的 MRO, MRO 中的那个类就是 type1 ,同时 issubclass(type2, type1) == True 。
那么, super() 实际上做了啥呢?简单来说就是:提供一个 MRO 以及一个 MRO 中的类 C , super() 将返回一个从 MRO 中 C 之后的类中查找方法的对象。
也就是说,查找方式时不是像常规方法一样从所有的 MRO 类中查找,而是从 MRO 的 tail 中查找。
举个栗子, 有个 MRO:
[A, B, C, D, E, object]
下面的调用:
super(C, A).foo()
super 只会从 C 之后查找,即: 只会在 D 或 E 或 object 中查找 foo 方法。
多继承中 super 的工作方式
再回到前面的
d = D() d.add(2) print(d.n)
现在你可能已经有点眉目,为什么输出会是
self is <__main__.D object at 0x10ce10e48> @D.add self is <__main__.D object at 0x10ce10e48> @B.add self is <__main__.D object at 0x10ce10e48> @C.add self is <__main__.D object at 0x10ce10e48> @A.add 19
了吧 ;)
下面我们来具体分析一下:
D 的 MRO 是: [D, B, C, A, object] 。 备注: 可以通过 D.mro() (Python 2 使用 D.__mro__ ) 来查看 D 的 MRO 信息)
-
详细的代码分析如下:
class A: def __init__(self): self.n = 2 def add(self, m): # 第四步 # 来自 D.add 中的 super # self == d, self.n == d.n == 5 print('self is {0} @A.add'.format(self)) self.n += m # d.n == 7 class B(A): def __init__(self): self.n = 3 def add(self, m): # 第二步 # 来自 D.add 中的 super # self == d, self.n == d.n == 5 print('self is {0} @B.add'.format(self)) # 等价于 suepr(B, self).add(m) # self 的 MRO 是 [D, B, C, A, object] # 从 B 之后的 [C, A, object] 中查找 add 方法 super().add(m) # 第六步 # d.n = 11 self.n += 3 # d.n = 14 class C(A): def __init__(self): self.n = 4 def add(self, m): # 第三步 # 来自 B.add 中的 super # self == d, self.n == d.n == 5 print('self is {0} @C.add'.format(self)) # 等价于 suepr(C, self).add(m) # self 的 MRO 是 [D, B, C, A, object] # 从 C 之后的 [A, object] 中查找 add 方法 super().add(m) # 第五步 # d.n = 7 self.n += 4 # d.n = 11 class D(B, C): def __init__(self): self.n = 5 def add(self, m): # 第一步 print('self is {0} @D.add'.format(self)) # 等价于 super(D, self).add(m) # self 的 MRO 是 [D, B, C, A, object] # 从 D 之后的 [B, C, A, object] 中查找 add 方法 super().add(m) # 第七步 # d.n = 14 self.n += 5 # self.n = 19 d = D() d.add(2) print(d.n)调用过程图如下:
D.mro() == [D, B, C, A, object] d = D() d.n == 5 d.add(2) class D(B, C): class B(A): class C(A): class A: def add(self, m): def add(self, m): def add(self, m): def add(self, m): super().add(m) 1.---> super().add(m) 2.---> super().add(m) 3.---> self.n += m self.n += 5 <------6. self.n += 3 <----5. self.n += 4 <----4. <--| (14+5=19) (11+3=14) (7+4=11) (5+2=7)
现在你知道为什么 d.add(2) 后 d.n 的值是 19 了吧 ;)
]]>文章来源:https://mozillazg.com/2016/12/python-super-is-not-as-simple-as-you-thought.html
众所周知,C/C++ 语言可以使用 #define 和 const 创建符号常量,而使用 enum 工具不仅能够创建符号常量,还能定义新的数据类型,但是必须按照一定的规则进行,下面我们一起看下 enum 的使用方法。
步骤(一)——枚举量的声明和定义
(1) 首先,请看下面的语句:
enum enumType {Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday};
这句话有两个作用:
- 第一:声明 enumType 为新的数据类型,称为枚举(enumeration);
- 第二:声明 Monday、Tuesday 等为符号常量,通常称之为枚举量,其值默认分别为 0-6。(后面会介绍怎样显式的初始化枚举量的值)
(2) 接着利用新的枚举类型 enumType 声明这种类型的变量:enumType Weekday 就像使用基本变量类型int声明变量一样,如 int a; 也可以在定义枚举类型时定义枚举变量
enum enumType {Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday}Weekday;
然而与基本变量类型不同的地方是,在不进行强制转换的前提下,只能将定义的枚举量赋值给该种枚举的变量,如:Weekday = Monday; 或者 Weekday = Sunday; 不能将其他值赋给枚举变量,如:Weekday = 10; 这是不允许的,因为 10 不是枚举量。也就是说 Weekday 只能是定义的 Monday-Sunday 这些定义过的枚举量。然而这不是绝对的,第六条会讲到利用强制类型转换将其他类型值赋给枚举变量。
(3) 上面讲不能将非枚举量赋给枚举变量,那么能不能将枚举量赋给非枚举变量呢?如:int a=Monday; 这是允许的,因为枚举量是符号常量,这里的赋值编译器会自动把枚举量转换为int类型。
(4) 前面讲可以对枚举进行赋值运算,那枚举变量能不能进行算术运算呢?
Weekday++;Weekday = Monday + Tuesday;
这是非法的,因为这些操作可能导致违反类型限制,比如:
Weekday = Sunday; Weekday++;
Weekday 首先被赋予枚举量中的最后一个值 Sunday(值为6),再进行递增的话,Weekday 增加到 7,而对于 enumType 类型来说,7 是无效的。
总结:对于枚举,只定义了赋值运算符,没有为枚举定义算术运算。
(5)不能对枚举量进行算术运算,那么枚举量能不能参与其他类型变量的运算呢?
int a; a = 1 + Monday;
这是允许的,因为编译器会自动把枚举量转换为 int 类型。
(6)第二条讲:在不进行强制转换的前提下,只能将定义的枚举量赋值给该种枚举的变量,言下之意就是可以通过强制转换将其他类型值赋给枚举变量:
Weekday = enumType(2);
等同于:
Weekday = Wednesday;但是,如果试图将一个超出枚举取值范围的值通过强制转换赋给枚举变量,会出现什么结果?
Weekday = enumType(20);
结果将是不确定的,这么做不会出错,但得不到想要的结果。
步骤(二)——自定义枚举量的值
(1) 前面讲通过定义 enum enumType {Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday}; 枚举量 Monday、Tuesday 等的值默认分别为 0-6,我们可以显式的设置枚举量的值:
enum enumType {Monday=1, Tuesday=2, Wednesday=3, Thursday=4, Friday=5, Saturday=6, Sunday=7};
指定的值必须是整数!
(2) 也可以只显式的定义一部分枚举量的值:
enum enumType {Monday=1, Tuesday, Wednesday=1, Thursday, Friday, Saturday, Sunday}; 这样 Monday、Wednesday 均被定义为 1,则 Tuesday=2,Thursday、Friday、Saturday、Sunday 的值默认分别为 2、3、4、5。
总结:未被初始化的枚举值的值默认将比其前面的枚举值大1。
(3) 第二条还说明另外一个现象,就是枚举量的值可以相同。
步骤(三)——枚举的取值范围
前面讲到可以通过强制转换将其他类型值赋给枚举变量:
Weekday = enumType(2);
这是合法的;
但是
Weekday = enumType(20);
是非法的。这里涉及枚举取值范围的概念:枚举的上限是 大于最大枚举量的 最小的 2 的幂,减去 1;
枚举的下限有两种情况:一、枚举量的最小值不小于 0,则枚举下限取 0;二、枚举量的最小值小于 0,则枚举下限是小于最小枚举量的最大的 2 的幂,加上 1。
举例来讲:
假如定义 enum enumType1 { First=-5,Second=14,Third=10 }; 则枚举的上限是 16-1=15(16大于最大枚举量14,且为2的幂); 枚举的下限是-8+1=-7(-8小于最小枚举量-5,且为2的幂);
步骤(四)——枚举应用
个人觉得枚举和 switch 是最好的搭档:
enum enumType{Step0, Step1, Step2}Step=Step0; // 注意这里在声明枚举的时候直接定义了枚举变量 Step,并初始化为 Step0
switch (Step)x
{
case Step0:{...;break;}
case Step1:{...;break;}
case Step2:{...;break;}
default:break;
}
另外枚举还有一种少见的用法是 enum { one ,two ,three}; 就是不指定一个名字,这样我们自然也没法去定义一些枚举类型了。此时就相当于 static const int one = 0; 这样定义三个常量一样。然后用的话就是 int no = one。
强类型枚举
一、简述
强类型枚举(Strongly-typed enums),号称枚举类型,是C++11中的新语法,用以解决传统C++枚举类型存在的缺陷。传统C++中枚举常量被暴漏在外层作用域中,这样若是同一作用域下有两个不同的枚举类型,但含有相同的枚举常量也是不可的,比如:
enum Side{Right,Left};
enum Thing{Wrong,Right};
这是不能一起用的。
另外一个缺陷是传统枚举值总是被隐式转换为整形,用户无法自定义类型。C++11中的强类型枚举解决了这些问题。
二、强类型枚举
强类型枚举使用enum class语法来声明,如下:
enum class Enumeration{
VAL1,
VAL2,
VAL3=100,
VAL4
};
这样,枚举类型时安全的,枚举值也不会被隐式转换为整数,无法和整数数值比较,比如(Enumeration::VAL4==10会触发编译错误)。
另外枚举类型所使用的类型默认为int类型,也可指定其他类型,比如:
enum calss Enum:unsigned int{VAL1,VAL2};
正如前面所说,强类型枚举能解决传统枚举不同枚举类下同枚举值名的问题,使用枚举类型的枚举名时,必须指明所属范围,比如:Enum::VAL1,而单独的VAL1则不再具有意义。
还有一点值得说明的是C++11中枚举类型的前置声明也是可行的,比如:
enum calss Enum; enum class Enum1:unsigned int;
三、项目中的强类型枚举代码片段
1、图像处理
enum class Color{RED,BLUE,YELLOR,BLACK,WHITE};
2.交通灯
enum class TrafficLight{RED,YELLOR,GREEN};
强类型枚举值具有传统枚举的功能——命名枚举值,同时又具有类的特点——具有类域的成员和无法进行默认的类型转换。所以也称之为枚举类——enmu class
枚举类的底层数据必须是有符号或无符号整型,比如 char unsigned int unsigned long,默认为 int。
3.前置声明应用
enmu class Clolor:char; //前置声明枚举类
void Foo(Color*p); //前置声明的使用
//....................
enum class Color:char{RED,GREEN,BLACK,WHITE}; //前置声明的定义
]]>参考:https://blog.csdn.net/u012333003/article/details/20612267
FS: 输入字段分隔符变量
FS(Field Separator) 读取并解析输入文件中的每一行时,默认按照空格分隔为字段变量,$1,$2...等。FS 变量被用来设置每一记录的字段分隔符号。FS 可以是任意的字符串或者正则表达式.你可以使用下面两种方式来声名FS:
使用 -F 命令选项
作为设置为普通变量使用
语法:
$ awk -F 'FS' 'commands' inputfilename
或者
$ awk 'BEGIN{FS="FS";}'
FS 可以是任意字符或者正则表达式
FS 可以多次改变, 不过会保持不变直到被明确修改。不过如果想要改变字段分隔符, 最好是在读入文本之前就改变 FS, 这样改变才会在你读入的文本生效。
下面是一个使用 FS 读取 /etc/passwd 以 : 作为分隔符的例子
$ cat etc_passwd.awk
BEGIN{
FS=":";
print "Name\tUserID\tGroupID\tHomeDirectory";
}
{
print $1"\t"$3"\t"$4"\t"$6;
}
END {
print NR,"Records Processed";
}
使用结果:
$ awk -f etc_passwd.awk /etc/passwd Name UserID GroupID HomeDirectory gnats 41 41 /var/lib/gnats libuuid 100 101 /var/lib/libuuid syslog 101 102 /home/syslog hplip 103 7 /var/run/hplip avahi 105 111 /var/run/avahi-daemon saned 110 116 /home/saned pulse 111 117 /var/run/pulse gdm 112 119 /var/lib/gdm 8 Records Processed
OFS: 输出字段分隔符变量
OFS(Output Field Separator) 相当与输出上的 FS, 默认是以一个空格字符作为输出分隔符的,下面是一个 OFS 的例子:
$ awk -F':' '{print $3,$4;}' /etc/passwd
41 41
100 101
101 102
103 7
105 111
110 116
111 117
112 119
注意命令中的 print 语句的, 表示的使用一个空格连接两个参数,也就是默认的OFS的值。因此 OFS 可以像下面那样插入到输出的字段之间:
$ awk -F':' 'BEGIN{OFS="=";} {print $3,$4;}' /etc/passwd
41=41
100=101
101=102
103=7
105=111
110=116
111=117
112=11
RS: 记录分隔符
RS(Record Separator)定义了一行记录。读取文件时,默认将一行作为一条记录。 下面的例子以 student.txt 作为输入文件,记录之间用两行空行分隔,并且每条记录的每个字段用一个换行符分隔:
$ cat student.txt Jones 2143 78 84 77 Gondrol 2321 56 58 45 RinRao 2122 38 37 65 Edwin 2537 78 67 45 Dayan 2415 30 47 20
然后下面的脚本就会从student.txt输出两项内容:
$ cat student.awk
BEGIN {
RS="\n\n";
FS="\n";
}
{
print $1,$2;
}
$ awk -f student.awk student.txt
Jones 2143
Gondrol 2321
RinRao 2122
Edwin 2537
Dayan 2415
在 student.awk 中,把每个学生的详细信息作为一条记录, 这是因为RS(记录分隔符)是被设置为两个换行符。并且因为 FS (字段分隔符)是一个换行符,所以一行就是一个字段。
ORS: 输出记录分隔符变量
ORS(Output Record Separator)顾名思义就相当与输出的 RS。 每条记录在输出时候会用分隔符隔开,看下面的 ORS 的例子:
$ awk 'BEGIN{ORS="=";} {print;}' student-marks
Jones 2143 78 84 77=Gondrol 2321 56 58 45=RinRao 2122 38 37 65=Edwin 2537 78 67 45=Dayan 2415 30 47 20=
上面的脚本,输入文件的每条记录被 = 分隔开。 附:student-marks 便是上面的输出.
NR: 记录数变量
NR(Number of Record) 表示的是已经处理过的总记录数目,或者说行号(不一定是一个文件,可能是多个)。下面的例子,NR 表示行号,在 END 部分,NR 就是文件中的所有记录数目。
$ awk '{print "Processing Record - ",NR;}END {print NR, "Students Records are processed";}' student-marks
Processing Record - 1
Processing Record - 2
Processing Record - 3
Processing Record - 4
Processing Record - 5
5 Students Records are processed
NF:一条记录的记录数目
NF(Number for Field)表示的是,一条记录的字段的数目. 它在判断某条记录是否所有字段都存在时非常有用。 让我们观察 student-mark 文件如下:
$ cat student-marks Jones 2143 78 84 77 Gondrol 2321 56 58 45 RinRao 2122 38 37 Edwin 2537 78 67 45 Dayan 2415 30 47
接着下面的Awk程序,打印了记录数(NR),以及该记录的字段数目: 因此可以非常容易的发现那些数据丢失了。
$ awk '{print NR,"->",NF}' student-marks
1 -> 5
2 -> 5
3 -> 4
4 -> 5
5 -> 4
FILENAME: 当前输入文件的名字
FILENAME 表示当前正在输入的文件的名字。 AWK 可以接受读取很多个文件去处理。看下面的例子:
$ awk '{print FILENAME}' student-marks
student-marks
student-marks
student-marks
student-marks
student-marks
在输入的文件的每一条记录都会输出该名字。
FNR: 当前输入文件的记录数目
当awk读取多个文件时,NR 代表的是当前输入所有文件的全部记录数,而 FNR 则是当前文件的记录数。如下面的例子:
$ awk '{print FILENAME, "FNR= ", FNR," NR= ", NR}' student-marks bookdetails
student-marks FNR= 1 NR= 1
student-marks FNR= 2 NR= 2
student-marks FNR= 3 NR= 3
student-marks FNR= 4 NR= 4
student-marks FNR= 5 NR= 5
bookdetails FNR= 1 NR= 6
bookdetails FNR= 2 NR= 7
bookdetails FNR= 3 NR= 8
bookdetails FNR= 4 NR= 9
bookdetails FNR= 5 NR= 10
附: bookdetails 与 student-marks 内容一样,作例子. 可以看出来 NR 与 FNR 的区别。
经常使用 NR 与 FNR 结合来处理两个文件,比如有两个文件:
$ cat a.txt 李四|000002 张三|000001 王五|000003 赵六|000004 $ cat b.txt 000001|10 000001|20 000002|30 000002|15 000002|45 000003|40 000003|25 000004|60
如果想作对应的话, 比如张三|000001|10
$ awk -F '|' 'NR == FNR{a[$2]=$1;} NR>FNR {print a[$1],"|", $0}' a.txt b.txt
张三 | 000001|10
张三 | 000001|20
李四 | 000002|30
李四 | 000002|15
李四 | 000002|45
王五 | 000003|40
王五 | 000003|25
赵六 | 000004|60
]]>英文原文:https://www.thegeekstuff.com/2010/01/8-powerful-awk-built-in-variables-fs-ofs-rs-ors-nr-nf-filename-fnr/
译文 :https://shomy.top/2016/05/05/trans-8-powerful-awk-built-in-variables/
我觉得可以从这5个维度再来聊聊指针。不过在聊之前,我写了个程序,把指针的"两己三他"维度都包含进来,然后再来一个一个解释每个维度的意思,你看看是不是这回事儿。
在大部分的使用指针的场景下,这5个维度应该足够帮你去理解了。不过在一些使用指针特殊的场景下,可能5维度法帮助不了你。
前方长文预警,若看的不耐烦了,可以收藏本文,有时间了接着看。
一、程序代码
1.1. 代码
实例
运行的结果如下:
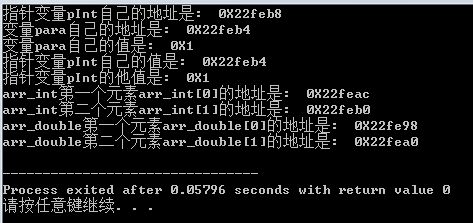
我在自己的文章里讲我自己理解的一些东西时,我很喜欢用非常简单的程序来阐明。所以那些认为要用天书般的程序来阐明观点的,或者鄙视低水平程序的大牛们,请忽略我^_^。
2.2. int型变量para
程序中:
int para = 1;
printf("变量para自己的地址是: 0X%x\n", ¶);
printf("变量para自己的值是: 0X%x\n", para);
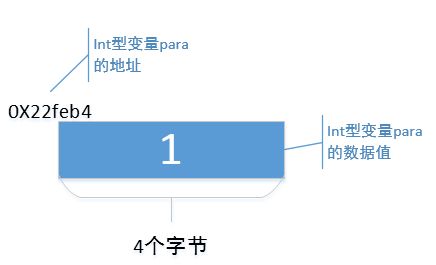
定义了变量para,它有自己的数据值,也有自己的存储地址,这些个都很好理解。从运行结果来看,变量para自己的数据值是16进制的"0X1",地址是16进制的"0X22feb4"。换句话说,在内存中,地址为"0X22feb4"开始的存储空间,有4个字节存储了一个数据值"0X1"。在我的机器上,一个int型变量占用4个字节,在你的机器上可能与我不一样。
关于int型变量para大家都好理解。下面,我来画一个示意图,来指明变量para在内存中存储的情况,如下:
下面开始说说"两己三他"的概念。
二、两己三他
"两己三他",展开来说,就是:己址、己值、他值、他址、他型。
2.1. 己址
2.1.1 "己址"的概念
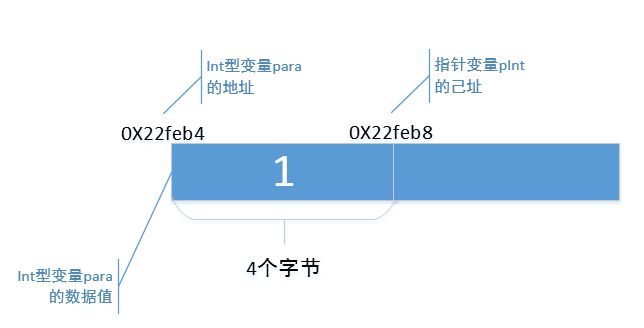
"己址",就是"自己的地址"的简称。指针pInt作为一个变量,与int变量para一样,也需要存储在内存中的一段存储空间,这段存储空间也会有一个开始地址,也就是说,指针变量pInt也会有自己的地址。上面说了,变量para的地址是 " 0X22feb4",那么,指针变量pInt的地址是啥呢?
2.1.2 "己址"的获取
我们都学过,"&"是一个取地址的运算符,在程序中:
printf("指针变量pInt自己的地址是: 0X%x\n", &pInt);
就是通过"&"来获取指针变量pInt的地址。从运行结果来看,指针变量pInt的地址是"0X22feb8"。在我的机器上,指针变量pInt也是占用4个字节,因此,指针变量pInt存储在开始地址是"0X22feb8"开始的4个字节空间。
2.1.3 "己址"的代码写法
在代码中,表示指针变量pInt的"己址"的代码写法,常见的是:
&pInt;
现在,我们来完善那个示意图,图中加入指针变量pInt的"己址",指出指针变量pInt在内存中是怎么个存储形式。
"己址",就是这个意思。你看,没什么特别难的吧!
2.2 己值
2.2.1 "己值"的概念
"己值",就是"自己的数据值"的简称。指针pInt作为一个变量,跟变量para一样,也有着自己的数据值。
2.2.2 "己值"的获取
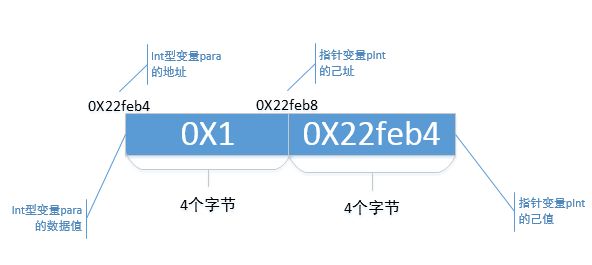
上面提到,变量para自己的数据值是"1",那么指针变量pInt自己的数据值是多少。在程序中:
pInt = ¶
printf("指针变量pInt自己的值是: 0X%x\n", pInt);
我通过"&"运算符,将变量para的地址值赋给了指针变量pInt,通过printf来输出指针变量pInt的数据值。从运行结果中来看,指针变量pInt自己的数据值是"0X22feb4"。我们再看,变量para的地址也是"0X22feb4",所以,
pInt = ¶
这个语句的本质,就是将变量para的地址,给了指针变量pInt的己值,这样就将指针变量pInt与变量para绑定在一起了。
在"己址"中提到了,指针pInt的数据值存储在地址为"0X22feb8"开始的4个字节的内存上,那么也就是说,地址为"0X22feb8"开始的内存,后面的4个字节都用来存储着一个数据值"0X22feb4"。
2.2.3 "己值"的代码写法
在代码中,表示指针变量pInt的"己值"的代码写法,常见的有
pInt;
也有的代码写法是:
pInt + N; pInt - N;
这种写法的意思是用pInt的"己值"加上一个数字N或者减去一个数字N,这个等讲到"他型"这个属性时会提到。也有的写法是:
pIntA - pIntB;
这种写法表示的是两个指针变量用"己值"做减法。
2.2.4 示意图
现在,继续来完善上面的示意图,加入指针变量pInt的己值。
所以,一般而言,"己值"对于指针变量pInt来讲,是自己的数据值;对其它的int类型的变量来讲,就是它们的地址。
2.3 他址
2.3.1 "他址"的概念
"他址"的概念就是"他人的地址"的意思。其实在上面提到己值时,就已经不那么明显地提到了"他址"的概念。
2.3.2 "他址"的获取
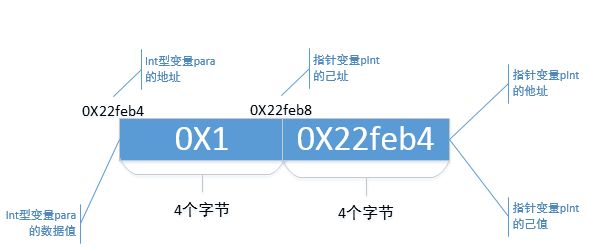
整型变量para存储在内存地址为"0X22feb4"开始的4个字节。在程序中,我通过
pInt = ¶
将变量para的地址给了指针变量pInt,这样就将指针变量pInt与变量para绑定在一起了。更为本质的说,是把"他人的地址"赋值给了指针变量pInt的"己值",这里,"他人的地址"的"他",指的就是变量para,"他人地址的址"的"址",指的就是变量para的地址。注意,你看,"他址"和"己值"在数据值上是一样的,所以,你领悟出了什么东西来了没?
很多教材所谓的"指针是一个地址变量,存储的是其它变量的地址",说白了,就是在说"他址"这个维度的数据值等于"己值"这个维度的数据值,只是教材没说的那么明白。
2.3.3 示意图
再来完善那个示意图,这次加入"他址"的概念。
2.4 他值
2.4.1 "他值"的概念
"他值",就是"他人的数据值"的意思。
2.4.2 "他值"的获取
在程序中,我通过
pInt = ¶
将变量para的地址给了指针变量pInt的"己值",这样就将指针变量pInt与变量para绑定在一起了。这个时候,"他人的数据值"的"他",指的就是变量para,"他人的数据值"的"数据值",指的就是变量para的数据值"1"。在程序中,我通过
printf("指针变量pInt的他值是: 0X%x\n", *pInt);
也就是指针变量pInt前面加上" * ",来输出指针变量的"他值",从运行结果来看,是"0X1"。 注意,你看,指针变量pInt的"他值",与变量para的数据值是一样的,你又领悟到了什么?想不出来吗?继续看!
2.4.3 "他值"的代码写法
你经常在代码中看到的那些个代码写法,比如什么*pInt写法,是在表达什么意思啊,其实就是在计算指针变量pInt的"他值"啊!
这些个写法呢:*(pInt + 1)、*pInt + 1、pInt[1]?
*(pInt + 1):如果把pInt + 1 看成是另外一个指针,比如
int *pTemp = pInt + 1;
那么*(pInt + 1)计算的本质上就是指针变量pTemp的"他值";
*pInt + 1:这个就是用pInt的"他值"加1;
pInt[1]:这个呢?其实就是*(pInt + 1)。
2.4.4 示意图
继续完善上面的示意图,这次加入"他值"的概念:
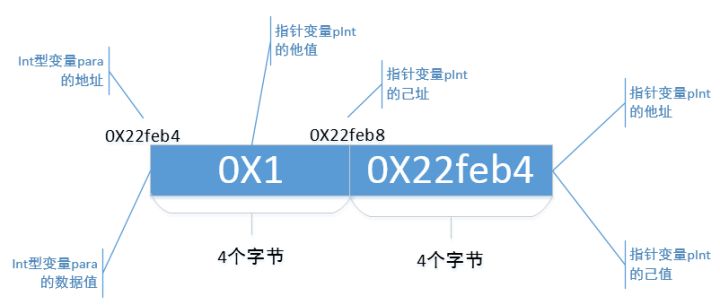
2.5 他型
2.5.1 "他型"的概念
"他型",就是"他人的类型"的简称。在程序中,我们看到,声明指针变量pInt时这样写的:
int *pInt = NULL;
指针变量pInt前面的" int "并不是说指针变量pInt的"己值"是一个int类型的数据值;而是说,指针变量pInt的"他值"是一个" int "类型的数据值,此处指针变量pInt的"他值"是变量para的数据值"0X1",因此,指针变量pInt前面的"int"指的就是数据值"0X1"是一个"int"型。
总之一句话,声明指针时的类型是用来修饰"他值"的,而不是"己值"。
你再看,在声明变量para的时候:
int para = 1;
变量para前面的"int"就是指变量para的类型是一个整型,此时的"int"对para来说是一个"自型",也就是"自己的类型"的意思,只有指针在声明时的类型是"他型",是"他人的类型"。
既然"他型"是来修饰"他值",那么在声明指针时还要加上这个"他型"有什么意义呢?继续看!
在程序中,如下代码片段:
int arr_int[2] = {1, 2};
pInt = arr_int;
printf("arr_int第一个元素arr_int[0]的地址是: 0X%x\n", pInt);
printf("arr_int第二个元素arr_int[1]的地址是: 0X%x\n", pInt + 1);
我把一个整型数组arr_int的地址赋给了指针变量pInt,那么pInt的"己址"没有变化,还是 0X22feb8,但是"己值"却变了。
刚才指针变量pInt的"己值"还是" 0X22feb4",也就是变量para的地址,现在变成了"0X22feac",这个可是数组arr_int第一个元素的地址。也就是说,指针变量pInt的"己址"不会改变,但是"己值"是可以被改变的。
现在我们来看看"pInt"与"pInt + 1"的区别,这是在用pInt的"己值"在做运算。从运行结果来看,pInt的"己值"此时是"0X22feac",而pInt + 1的"己值"是" 0X22feb0",你发现了吗,两者正好相差4个字节,而一个"int"类型的数据也正好占用了4个字节。
你可能会认为,既然pInt + 1是用"己值"加1,那么应该是"0X22feac + 1" = "0X22fead"才对啊,为什么不是这样呢?这就是指针变量pInt的"他型"搞的鬼。
"他型"的意思,用大白话来说,就是:"我说 pInt 大兄弟啊,你的他值是个int型的数据值,你今后要是用你的己值 +1,+2,或者 -1,-2,可千万别傻乎乎的就真的加1个字节,加2个字节, 或者就真的减1个字节、减2个字节。人家int类型占4个字节,你就得按照4个字节为一个单位,去加 1* 4个字节 、2 * 4个字节,或者减去1 * 4个字节、2 * 4个字节,知道不?哦,顺便说下,pInt + N的N,可以为正数也可以为负数"。
当然啦,如果你的机器上"int"型数据占8个字节,那么pInt + 1就是在"己值"上加8个字节,pInt + 2就是在"己值"上加 8 *2 = 16个字节,就这么个意思。
我在程序中又举了个例子来说明这个"他型"。程序如下:
double *pDouble = NULL;
double arr_double[2] = {1.1, 2.2};
pDouble = arr_double;
printf("arr_double第一个元素arr_double[0]的地址是: 0X%x\n", pDouble);
printf("arr_double第二个元素arr_double[1]的地址是: 0X%x\n", pDouble + 1);
这次声明一个指针变量pDouble,它的"他型"是个"double"型,它的"己值"是数组arr_double的地址,它的"他值"是数组arr_double[0]这个元素的数据值" 1.1 "。在我的机器上,一个double型占用8个字节,那么pDouble + 1就是用pDouble 的"己值"加 1 * 8个字节,pDouble + 2就是用pDouble 的"己值" 加 2 * 8= 16个字节,pDouble - 1就是pDouble 的"己值"减去 1 * 8个字节,pDouble - 2就是pDouble 的"己值"减去 2 * 8 = 16个字节,我滴个乖乖!朋友们可以对着运行结果自己计算对不对!
3. 总结
是时候来总结下了。
我声明一个指针变量:
type *pType = NULL;
pType有5个维度,分别是:
pType = (己址,己值,他址,他值,他型);
3.1 己址:即"自己的地址"
指针变量pType作为一个变量,也有自己的地址,常见的代码写法是"&pType "。
己址在一般的程序中不会被频繁地用到,如果要用的话,就涉及到"指针的指针",这又是另外一个话题了,本文不讨论;
3.2 己值:即"自己的数据值"
指针变量pType 作为一个变量,也有自己的数据值,代码的写法是"pType "。
也可以在己值上做加减法运算,常见的代码写法有"pType + N"、"pType - N"、"pType2 - pType1"等。
3.3 他址:即"他人的地址"
指针变量pType的己值,意义除了表示自己的数据值外,还表示了与pType绑定在一起的"type"类型的变量的地址。一般而言,指针变量pType的"己值"与"他址"在数据值上是一样的。
将一个type类型的变量与pType绑定在一起的常见方式是:pType = &变量;
3.4 他值:即"他人的数据值"
一旦type类型的变量与pType绑定在一起,指针变量pType可以通过一些代码写法,来获取type类型变量的值,也就是"他值"。常见的代码写法有:" *pType "、" pType-> "等。
而这些代码的写法:" *(pType + N) "、" *(pType - N) "、" pType[N]"也是获取的"他值",不过需要特别说明一下:
pType + N 你可以看成是:
type *pTemp = pType + N;
" *(pType + N) "其实计算的就是指针变量pTemp的"他值"。
" *(pType - N) " 你就好理解了吧;
" pType[N]"其实就是" *(pType + N) ",你就死记硬背吧。
3.5 他型:即"他人的类型"
声明指针变量pType时,前面的"type"不是用来修饰pType 的"己值"的,而是用来修饰"他值"的,也就是说,"type"不是说pType的"己值"是一个type类型的数据值,而是指pType 的"他值"是一个type类型的数据值。
"他型"在代码中的作用,主要是计算"pType + N"、"pType - N"时,pType要加上或者减去 ( N * sizeof(type) )个字节。
指针总是让人晕晕的,很可能就是让你晕在这5个维度里的一个或者几个上。把这5个维度好好理解透,指针啊,只是个纸老虎。
4. 习题讲解
讲完了5个维度,不来点上手习题怎么行。下面列举几个习题,都是跟指针有关的,都是让初学者晕的歇菜的。我用这5个维度来解读这些题,你看看是不是要轻松一点!
4.1 数组元素求和
4.1.1 程序
第一个例题是很常见的程序,就是求一个数组元素的和,程序如下:
实例
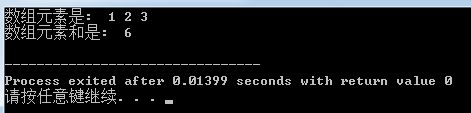
程序很简单,先是输出数组的所有元素,然后计算出数组所有元素的和。运行结果如下:
4.1.2 "两己三他"的解读
4.1.2.1 输出数组元素
在输出数组元素时,代码如下:
pArr = arr;
printf("%d ", pArr[index]);
这句代码等同于
pArr = arr;
printf("%d ", *( pArr + index));
这里面使用了"己值"、"他型"做了加法运算,使用了"他值"获取数组元素。
"己值":代码先是将数组名 arr的数据值赋值给了pArr的"己值"。而数组名arr的数据值是啥啊,是arr[0]元素的地址,对吧!那么pArr的己值,也是arr[0]的地址,对吧!这样一来,pArr就和arr[0]绑定起来了。
至于( pArr + index)的意思呢,你就看成有一个间接的、临时的指针变量pTemp:
int *pTemp = pArr + index;
也就是说,pArr + index其实也是一个指针pTemp,只不过这个pTemp的己值是pArr的己值加上 index * sizeof(int) 个字节数。
"他型":pArr的他型是"int"型,pArr + index,是在pArr己值的基础上,加多少个字节呢?pArr的他型是int型,那么pArr + index,是不是意味着pArr的己值加上 index * sizeof(int) 个字节啊!
pArr:可以写成pArr + 0,就是加上 0 * 4 = 0个字节,此时pTemp的己值是arr[0]的地址;
pArr + 1:就是加上1 * 4 = 4 个字节,此时pTemp的己值是arr[1]的地址;
pArr + 2:就是加上2 * 4 = 8 个字节,此时pTemp的己值是arr[2]的地址;
这样,pArr + index就遍历到了数组所有元素的地址了。
你会发现,pTemp的己值,一直在发生变化;pArr的己值和己址,一直未变。
"他值":既然pArr + index能够遍历到数组所有元素的地址,再使用 *(pArr + index) ,也就是*pTemp,是不是就能获取到pTemp的他值了,这样也就变量到数组所有元素的值了!
4.1.2.2 数组元素求和
求数组元素的和时,使用的代码如下:
sum = sum + *(pArr + index);
根据刚才我对输出数组元素的分析,这句代码中pArr是怎么玩的,大家也清楚了吧!
pArr + index依然是在用pArr的己值做加法运算,获取到一个临时指针pTemp的己值,这个pTemp的己值是每个数组元素的地址;
再用 *(pArr + inedx),也就是*pTemp, 获取临时指针pTemp的他值,也就是每个元素的值。
最后将pTemp的每一个他值,叠加起来,算出数组元素的和。
4.1.2.3 总结
大家试着用"两己三他"的维度去理解pArr、pArr + index、*(pArr + index)、pArr[index]、*pArr + index等常见的代码写法!
4.2 指针数组
指针数组是将指针与数组结合起来的东东,对于初学者朋友而言,会比较难理解。指针数组是一个比较大的话题,相关概念请参见一般的C语言教材,这里只是用"两己三他"的概念来解释程序中的指针部分概念。
4.2.1 程序
指针数组,我举了一个例子如下:
实例
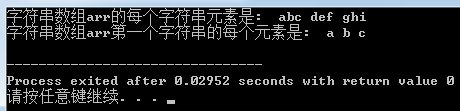
运行结果如下:
4.2.2 "两己三他"的解读
4.2.2.1 输出所有的字符串
先看指针数组的定义:
char *arr[3] = {"abc", "def", "ghi"};
你看到的这个数组的每个元素好像是一个字符串,其实本质上是这样的:
char *pChar1 = "abc", *pChar2 = "def", *pChar3 = "ghi";
char *arr[3] = {pChar1, pChar2, pChar3};
数组arr的每个元素其实是一个"他型"是"char"的指针。
arr[0]就是pChar1这个指针,那么pChar1的己值或者他址是啥,当然是字符串"abc"的字符'a'的地址,那么:
printf("%s ", arr[0]);
本质上是:
printf("%s ", pChar1);
使用pChar1的己值或者他址,从字符'a'的地址开始,一个一个地输出后面的'b'和'c'。
对于pChar2和pChar3也是一样地理解。
4.2.2.2 输出第一个字符串"abc"的每个字符
代码如下:
char *pArr = arr[0];
printf("%c ", *(pArr + index) );
将arr[0],也就是pChar1的己值给了pArr的己值,那么pArr的己值和他址都是字符'a'的地址。
pArr + index 是在pArr的己值上,加上 index * sizeof(char) 个字节,给了一个临时指针变量pTemp:
char *pTemp = pArr + index;
这个指针pTemp的己值或者他址,会依次为字符'a', 'b', 'c'的地址,也就是pTemp的他值也会依次为字符'a', 'b','c',这样指针pTemp就会依次遍历到字符串"abc"的每一个字符了。
4.3 链表
链表是使用指针最为频繁的,什么插入节点、删除节点等,都会遇到如下的代码写法:
p2 = p1->next; p1->next = p3->next; ......
这TM什么玩意儿,晕的一腿啊!这个next指针,那个next指针,跳来跳去的,我了个去,头脑已经充满浆糊了。呵呵,指针5维度分析法来了!不过,关于链表,我觉得还是另外开辟一个文章讲吧。等把链表讲完,回头再讲这些个next指针,我跟你讲,链表的本质也就那样,你懂了之后,链表比指针还要纸老虎。
]]>作者:石家的鱼
来源:https://zhuanlan.zhihu.com/p/27974028
在继承体系中,假设派生类想要使用基类的构造函数,须要在构造函数中显式声明。
例如以下:
在这里,B派生于A,B
又在构造函数中调用A的构造函数。从而完毕构造函数的传递。
又比方例如以下。当B中存在成员变量时:
如今派生于A的结构体B包括一个成员变量,我们在初始化基类A的同一时候也初始化成员d。如今的问题是:假若基类用于拥有为数众多的不同版本号的构造函数。这样,在派生类中按上面的思维还得写非常多相应的"透传"构造函数。例如以下:
非常明显当基类构造函数一多,派生类构造函数的写法就显得非常累赘,相当不方便。
二、问题的解决
我们能够通过using声明来完毕这个问题的简化,看一个样例
代码中基类和派生类都声明了同名的函数f。但派生类中办法和基类的版本号不同,这里使用using声明,说明派生类中也使用基类版本号的函数f。这样派生类中就拥有两个f函数的版本号了。在这里须要说明的是,假设没有使用using声明继承父类同名函数,那么派生类中定义的f函数将会屏蔽父类的f函数,当然若派生类根本就未定义这个f同名函数。还会选择用基类的f函数。
这样的方法,我们一样可迁移到构造函数的继承上。即派生类能够通过using语句声明要在子类中继承基类的全部构造函数。例如以下:
如今,通过using A::A的声明。将基类中的构造函数全继承到派生类中,更巧妙的是,这是隐式声明继承的。即假设一个继承构造函数不被相关的代码使用,编译器不会为之产生真正的函数代码,这样比透传基类各种构造函数更加节省目标代码空间。 但此时另一个问题:
当使用using语句继承基类构造函数时。派生类无法对类自身定义的新的类成员进行初始化,我们可使用类成员的初始化表达式,为派生类成员设定一个默认初始值。比方:
注意:
1.对于继承构造函数来说,參数的默认值是不会被继承的,并且,默认值会 导致基类产生多个构造函数版本号(即參数从后一直往前面减。直到包括无參构造函数,当然假设是默认复制构造函数也包括在内),这些函数版本号都会被派生类继承。
2.继承构造函数中的冲突处理:当派生类拥有多个基类时,多个基类中的部分构造函数可能导致派生类中的继承构造函数的函数名。
參数都同样,那么继承类中的继承构造函数将导致不合法的派生类代码,比方:
在这里将导致派生类中的继承构造函数发生冲突,一个解决的办法就是显式定哟继承类的冲突构造函数。阻止隐式生成对应的继承构造函数,以免发生冲突。
3.假设基类的构造函数被声明为私有构造函数或者派生类是从基类虚继承的,那么就不能在派生类中声明继承构造函数。
4.假设一旦使用了继承构造函数,编译器就不会为派生类生成默认构造函数。这样,我们得注意继承构造函数无參版本号是不是有须要。
]]>来源:https://www.cnblogs.com/yangykaifa/p/6737354.html