通俗点说,两个角色,一种goroutine作为一个worker(他是个小弟),老老实实干活。另一种goroutine作为管理者督促小弟干活(它自己也是个worker)。
在有很多小弟干活时,管理者没事干歇着,但同时它又希望得到一个通知,知道小弟们什么时候干完活(所有小弟们一个不少全都干完活了)。这样管理者好对小弟的工作成果做验收。
如果没有sync.WaitGroup,怎么实现?
其实也不难,从程序开发角度看,就是维护一个小弟总数和一个通道。每个小弟干完活,就往通道发一个空消息,
管理者阻塞在通道的监听上。来一个消息就说明有一个小弟干完活了,记录下有多少个消息,消息个数和小弟总数一致。就说明全干活了,管理者关闭通道,验收小弟工作成果。
写成代码就是这样子
workers := 3ch := make(chan struct{})worker := func() {
// 干活干活干活 ch <- struct{}{} // 通知管理者}leader := func() {
cnt := 0
for range ch {
cnt++
if cnt == workers {
break
}
}
close(ch)
// 检查工作成果}go leader()for i := 0; i < workers; i++ {
go worker()}改成sync.Waitgroup实现同样的功能就成这样子
wg := sync.WaitGroup{}workers := 3wg.Add(workers)worker := func() {
defer wg.Done()
// 干活干活干活}leader := func() {
wg.Wait()
// 检查工作成果}go leader()for i := 0; i < workers; i++ {
go worker()}Add,Done,Wait。三招完事。
语义很清晰。
知识点:sync.WaitGroup可以解决同步阻塞等待的问题。一个人等待一堆人干完活的问题得到优雅解决。
到此为止就是sync.WaitGroup的常规用法了。举一反三,可能还想到其它用法?文章最后一部分揭晓 :P
实现原理
根据语义猜测下,肯定是离不开阻塞唤醒机制和次数加减。而且是并发环境,那么次数加减要CAS。最后还要记录下阻塞的goroutine个数,因为要把挨个他们唤醒。
本文原理不多写,简单介绍下数据结构,再给出带注释的源码,大家自行理解下。(如果看过《一份详细注释的go Mutex源码》应该会很容易理解)
数据结构:
type WaitGroup struct {
noCopy noCopy
state1 [12]byte
sema uint32}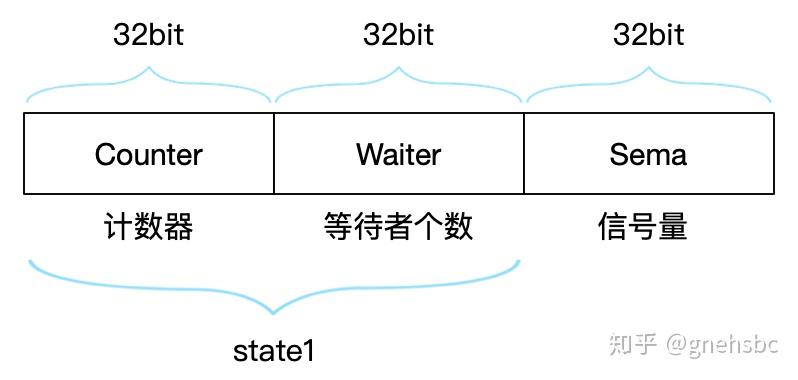
如图,除了state1其它没什么好说的。
state1是12字节,但图里面只有8字节。原因是32位编译器的问题,在取state1时是做了特殊处理。
func (wg *WaitGroup) state() *uint64 {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1)) // 32位系统 } else {
return (*uint64)(unsafe.Pointer(&wg.state1[4])) // 64位系统 }}Add、Done和Wait注释源码
func (wg *WaitGroup) Add(delta int) {
statep := wg.state()
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32) // 计数器 w := uint32(state) // 等待者个数。这里用uint32,会直接截断了高位32位,留下低32位 if v < 0 {
// Done的执行次数超出Add的数量 panic("sync: negative WaitGroup counter")
}
if w != 0 && delta > 0 && v == int32(delta) {
// 最开始时,Wait不能在Add之前被执行 panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
if v > 0 || w == 0 {
// 计数器不为零,还有没Done的。return // 没有等待者。return return
}
// 所有goroutine都完成任务了,但有goroutine执行了Wait后被阻塞,需要唤醒它
if *statep != state {
// 已经到了唤醒阶段了,就不能同时并发Add了 panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 清零之后,就可以继续Add和Done了 *statep = 0
for ; w != 0; w-- {
// 唤醒 runtime_Semrelease(&wg.sema, false)
}}func (wg *WaitGroup) Done() {
wg.Add(-1)}func (wg *WaitGroup) Wait() {
statep := wg.state()
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32) // 计数器 w := uint32(state) // 等待者个数 if v == 0 {
// 如果声明变量后,直接执行Wait也不会有问题 // 下面CAS操作失败,重试,但刚好发现计数器变成零了,安全退出 return
}
if atomic.CompareAndSwapUint64(statep, state, state+1) {
if race.Enabled && w == 0 {
race.Write(unsafe.Pointer(&wg.sema))
}
// 挂起当前的g runtime_Semacquire(&wg.sema)
// 被唤醒后,计数器不应该大于0 // 大于0意味着Add的数量被Done完后,又开始了新一波Add if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
return
}
}}举一反三
前文说过常规用法是解决一个人等待一堆人干完活的问题。
那反过来,一堆人等一个人干完活呢?或者一堆人等另一堆人干完活呢?
Add方法里最后的for循环代码告诉我们是可以的。
for ; w != 0; w-- {
// 唤醒全部被阻塞的goroutine runtime_Semrelease(&wg.sema, false)}
这样子就有点意思了。sync.WaitGroup就有点像发布订阅,只不过订阅者收到的不是消息,而是一种事件信号。
singleflight就是这样的例子。它解决了一堆人等一个人干完活的问题。就比如现在有100个线程同时请求数据库中同一行数。但只能有一个线程能读库,其他线程都阻塞等待它的结果。
源码也是短小精悍。其实仔细看,在高并发的情况下,singleflight的保证是分批式的。因为它会delete操作,只要delete操作抢锁成功,后来者们就组成新的一批,而这一批保证只有一个goroutine被执行。
使用singlefilght也有要注意的地方,fn的错误重试要自己处理;fn的耗时会成为别的goroutine最低耗时。
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
g.mu.Unlock()
// 一堆人都阻塞在这儿等一个人干完活 c.wg.Wait()
return c.val, c.err
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err}所以,一堆人等另一堆人干完活问题的思路也很简单。就不介绍啦。

发表评论 取消回复